

Why Financial Products Need Explainable States
.jpg)
Financial products are full of states: pending, verified, failed, retrying, under review, blocked, approved, declined, complete.
To a backend system, those states may look like fields in a database. To a user, they are much more than that. They answer urgent questions: Can I keep going? Do I need to do something? Is my money safe? Did I make a mistake? Am I stuck?
This article explains why explainable state is an engineering requirement in fintech, not just a UX improvement, and what it takes to build state that can explain itself.
For people building or rebuilding credit, an unclear state can make a product feel inaccessible. A user may be willing to complete onboarding, verify identity, connect a bank account, or resolve a payment issue, but they need to understand what is happening and what comes next.
Why do financial products need explainable states?
Financial products need explainable states because their states (pending, under review, retrying, declined) directly answer urgent user questions about money, access, and next steps — so ambiguity erodes trust and makes the product harder to operate. Clear state design matters because:
- It builds user trust: Users know whether they can continue, must act, or need to wait.
- It serves multiple audiences: Users, support, compliance, and engineers each need different context from the same state.
- It separates retryable from terminal: Users aren't told to retry steps that will never work.
- It prevents stale "pending" states: Users don't disappear into a status that never progresses.
- It improves credit access: A legible, recoverable process helps underserved users complete steps.
State Is How Users Understand Trust
At Atlas, our financial product asks users to do things that require trust. We may ask for identity information, bank connection, repayment authorization, income context, or supporting documents. When a user completes one of those steps, they expect the product to respond clearly.
We have learned that the worst experience is not always a hard failure. Sometimes it is ambiguity.
“Pending” can mean many things. It might mean the system is still processing. It might mean a partner has not responded. It might mean the user needs to retry. It might mean a human review is required. It might mean the state is stale and no one knows yet.
If the product does not distinguish those cases internally, it cannot explain them externally.
That is why state design matters. A good state model gives the product, support team, operations team, and backend systems a shared understanding of where the user is in the flow.
The Same State Has Multiple Audiences
One challenge in fintech is that a single state often serves multiple audiences.
The user needs plain language. They need to know whether they can continue, whether they need to take action, and what to expect.
- Support agents need operational context. They need to understand whether a user is waiting on processing, missing information, blocked by a known issue, or eligible for a retry path.
- Risk and compliance teams need traceability. They need to know what checks happened, when they happened, and why the system reached a particular state.
- Engineers need debuggability. They need to know which service wrote the state, whether the transition was valid, and whether the state can be retried safely.
If one overloaded status field tries to satisfy all of those audiences, the system becomes fragile. A better design separates machine state, user-facing copy, operational context, and audit history.
This is why state should be observable. Operations teams can prioritize queues based on state. Engineers can build alerts around stuck transitions. Product teams can identify confusing steps by watching where users pause or retry. Compliance teams can review decision paths with better context. But observability only works if state transitions leave something useful behind — which means it should be designed in, not reconstructed from scattered logs after the fact.
A General State Model
A simplified onboarding or verification flow might look like this:
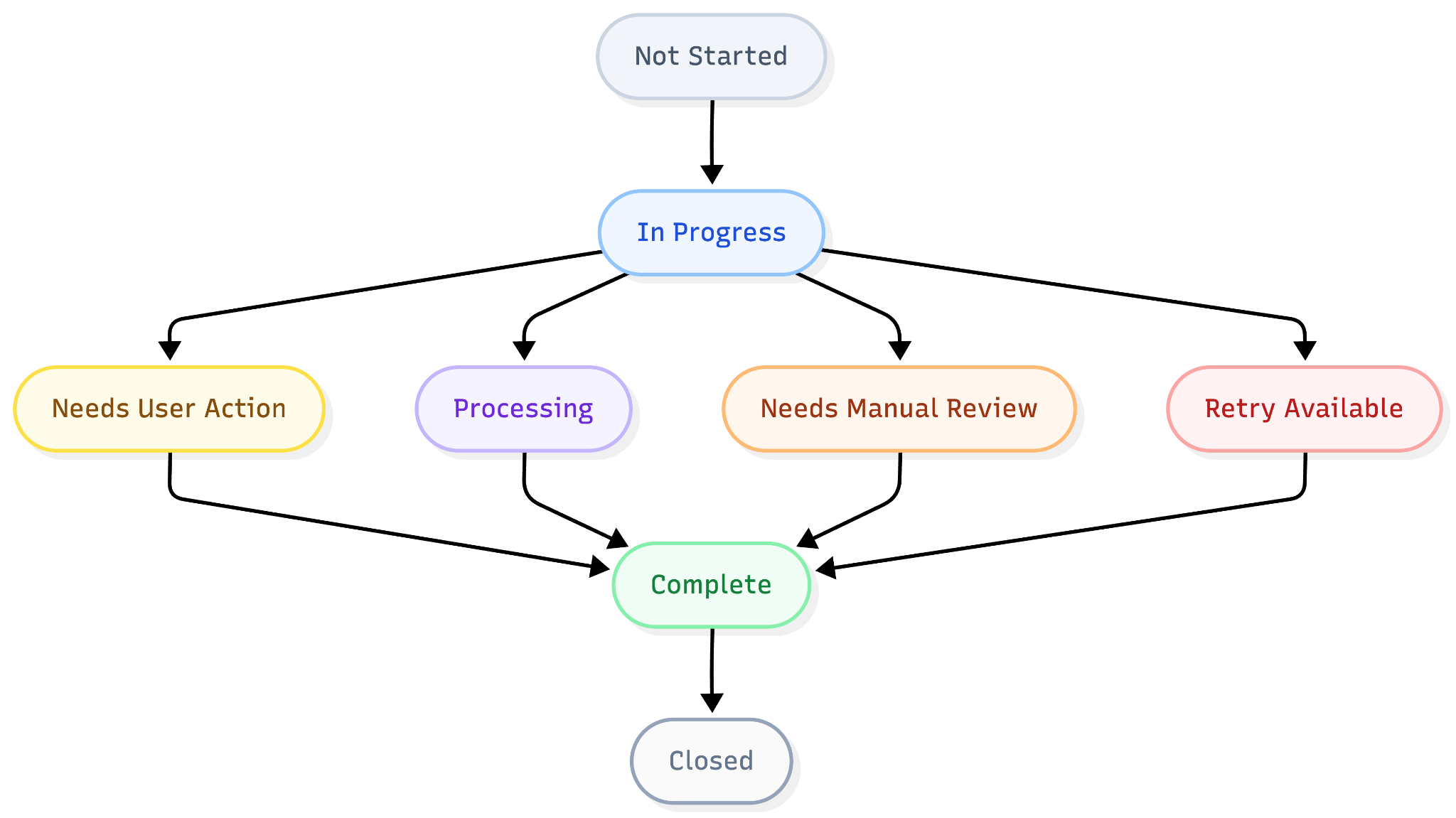
This diagram is intentionally generic. The important idea is that each state should answer a product question. These include:
- Not Started: The user has not begun.
- In Progress: The user is actively moving through the flow.
- Needs User Action: The user can do something to continue.
- Processing: The system or a partner is working.
- Needs Manual Review: A human or operational process is needed.
- Retry Available: The prior attempt failed in a recoverable way.
- Complete: The flow is finished.
- Closed: The flow ended and should not be retried through the same path.
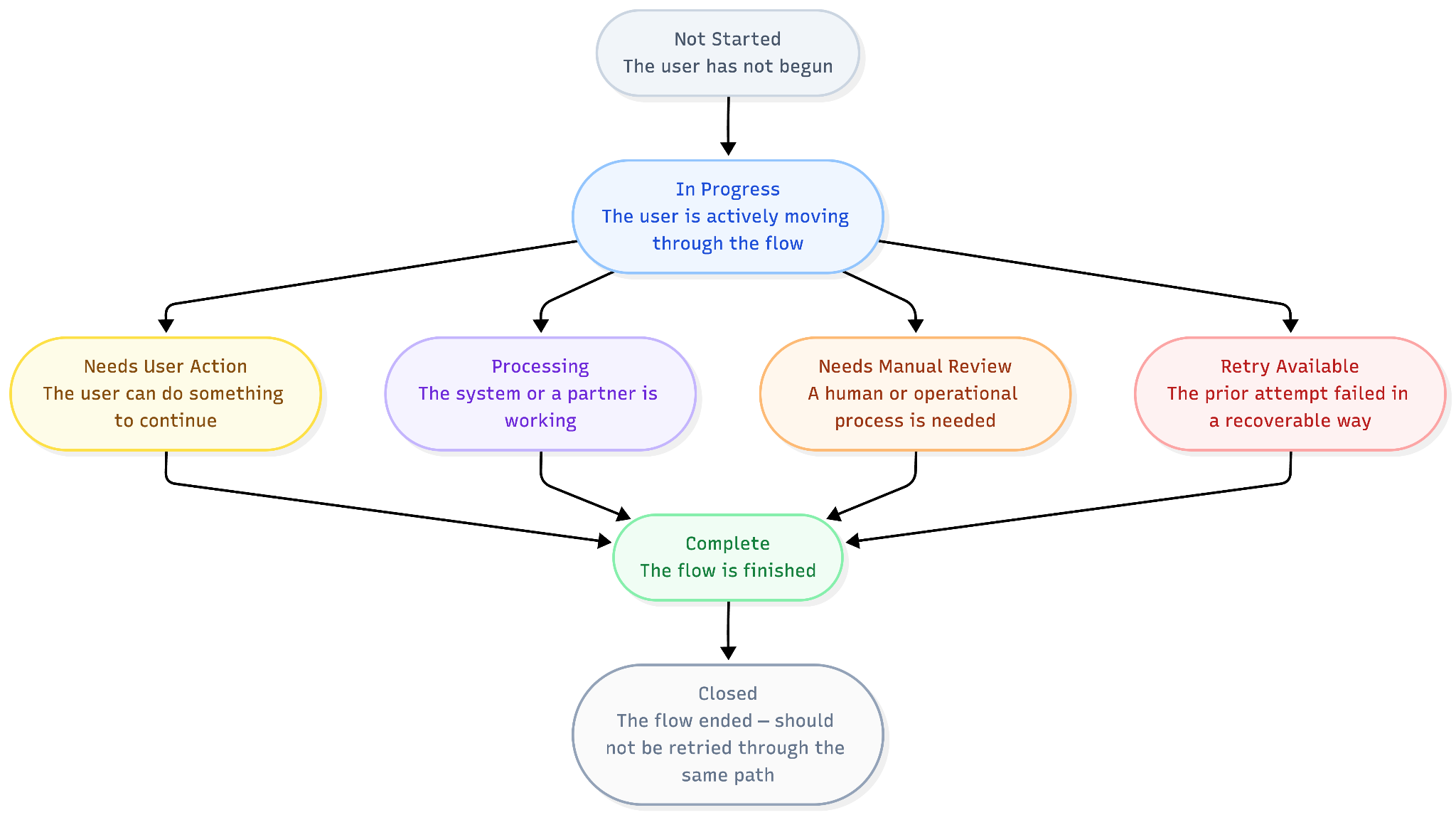
The details vary by product, but the discipline is reusable: states should be mutually understandable, not just technically possible.
Represent State So It Can Explain Itself
One mistake teams often make is treating product state as a single status string. A value like pending may be easy to store, but it is not very useful when different teams need to understand what is actually happening.
- To a customer, pending means: “Am I approved? Do I need to do anything?”
- To support, it means: “Can I explain this clearly, and is there a next step?”
- To operations or compliance, it means: “Is this waiting on a user action, a partner response, a manual review, or an internal process?”
- To engineering, it means: “Which system wrote this state, when did it change, and can we safely retry it?”
A more explainable pattern is to separate those concerns instead of forcing one field to carry all of them. A flow may keep a canonical machine status, a structured reason category, timestamps, writer or request metadata, retryability information, and a process or correlation ID.
For example, rather than thinking only in terms of:
{
"status": "pending"
}
a more explainable system might represent the same moment with separate concepts:
{
"status": "in_review",
"reason_category": "identity_verification",
"retryable": false,
"last_updated_at": "...",
"process_id": "..."
}
The exact field names are less important than the separation of meaning. The customer-facing product can use this information to show a clear next step. Support can understand the category of the issue without seeing sensitive vendor details. Engineering can trace the state back to the workflow that produced it.
This is especially important in financial products because many outcomes are not simple success or failure. A user may be waiting on identity verification, bank account linking, underwriting review, payment settlement, fraud checks, or an external partner response. If all of those become pending, the product becomes harder to explain and harder to operate.
For example, a single “pending” can become four more honest answers:
- Processing: We are checking information, and there is nothing for the user to do yet.
- Needs User Action: The user needs to complete one more step.
- Needs Manual Review: A person or internal process needs to review the case.
- Retry Available: A recoverable step failed, and the user or system can try again safely.
Those states may feel similar from the outside, but they require different product messages, support playbooks, backend behavior, and operational controls.
Engineering Tradeoffs
Making state explainable does add discipline to the write path. Engineers need to think about which transitions are valid, which fields are safe to expose, and which details should remain internal.
But that discipline is valuable because financial products are not only software systems. They are decision systems that affect real people.
Teams can implement explainable state with a state-machine library, explicit transition helpers, workflow-specific status mapping, or a domain-specific process tracker. The implementation choice depends on the product surface and risk level. The key requirement is the same: transitions should be intentional, observable, and hard to perform accidentally.
For higher-risk flows, a robust design should answer questions like:
- What states are terminal?
- Which failures are retryable?
- Which states require user action?
- Which states require manual review?
- Which system is allowed to move the application forward?
- How do we prevent a stale job, webhook, or retry from overwriting a newer decision?
- How can support and compliance understand what happened without needing an engineer to read logs?
These questions are not just backend implementation details. They shape the experience a user has when something does not go perfectly.
Retryable Is Not The Same As Failed
One of the most important distinctions is retryable versus terminal.
A retryable failure means the user or system can safely attempt the step again. A terminal failure means the flow ended, or a different path is required.
Mixing those together creates bad experiences. Users may be told to retry something that will never work. Support agents may escalate issues that the product could recover from automatically. Engineers may accidentally run duplicate checks or create inconsistent records.
Retry design should be explicit:
- What failed?
- Is it safe to retry?
- Who can retry it: user, support, backend job, or reviewer?
- Does retrying require new input?
- How do we prevent duplicate side effects?
- What should the user see while retry is happening?
Most of those questions have routine engineering answers, but “how do we prevent duplicate side effects?” is one of the most important in fintech.
A retry is not always harmless. If the operation touches money movement, account linking, identity checks, application submission, or a partner workflow, retrying the wrong way can create duplicate work or inconsistent records.
That is why idempotency matters. The same event or request should not accidentally produce multiple outcomes. A retry should be recognized as part of the same operation, not treated as a brand-new action every time.
This is where backend engineering and user experience meet. A retry is not just a button. It is a state transition with safety requirements.
Manual Review Should Be A First-Class State
Many financial flows cannot be fully automated. Identity checks, payment investigations, application reviews, and risk workflows sometimes need human judgment.
Manual review should not be treated as an error. It should be represented as a real state with its own expectations.
When manual review is first-class, the system can show better user messaging, route work to the right internal queue, record reviewer decisions, and prevent unrelated automation from racing ahead.
It also helps support teams. Instead of guessing whether a user is “stuck,” support can see that the user is in a review state and understand what kind of review is pending.
For engineers, this reduces ambiguity. A system that explicitly models manual review is easier to reason about than one where manual work is hidden inside comments, flags, or side channels.
State Transitions Need Ownership And Rules
A state model is only useful if transitions are controlled.
In distributed systems, many services may be able to observe the same user, application, or transaction. That does not mean every service should be allowed to change every state.
Good state design defines ownership:
- Which system can move the flow forward?
- Which system can mark a state complete?
- Which system can request manual review?
- Which system can reopen or retry?
- Which transitions are forbidden?
Ownership answers who may transition. Rules answer which transitions are valid.
For higher-risk flows, a robust design should define legal transitions and protect against stale writes. Some systems centralize writes through one owning service. Others use transactions, version checks, idempotent event keys, or workflow-specific guards.
The exact mechanism depends on the system, but the principle is the same: state should not drift accidentally.
Without transition ownership, a user may appear complete in one system and pending in another. A support tool may show stale information. A background job may overwrite a newer review decision. In fintech, that is not just messy. It can affect user trust.
Designing For Stale, Partial, And External Events
Financial systems often depend on partners and external networks. That means state changes may arrive late, out of order, or more than once.
A webhook may be retried. A user may refresh the app in the middle of a flow. A background job may reconcile data after the product surface has already shown an intermediate state. A partner response may be delayed. A user may complete one step while another system is still processing a previous one.
This is why an explainable state needs more than good labels. It also needs operational guardrails.
One useful pattern is idempotency: the same event or request should not accidentally create multiple outcomes. Another is correlation: related actions should be tied together so engineers and operators can reconstruct the path of a decision.
For complex flows, process timelines can help show not only the current state, but how the system arrived there. That makes debugging easier, and it also makes the product more humane.
A useful audit record should capture: actor, transition, reason, timestamp, correlation ID, and result. For higher-risk changes, before/after context makes review stronger.
When a user contacts support, the answer should not be “the system says pending.” A better system gives the support team enough context to say whether the user needs to wait, retry an action, submit more information, or expect a manual review.
Pending Is Not Forever
One of the most dangerous states in a financial product is a pending state that quietly becomes stale.
A system may be waiting for a callback that never arrives. A partner response may fail after the product has already moved forward. A background task may stop before completing the transition. A user may be left in a state where nothing is technically broken, but nothing is progressing either.
Explainable states should plan for that.
A strong state model usually includes expectations about how long processing states should last and what should happen when they exceed that expectation. Sometimes the right next step is a retry. Sometimes it is a manual review. Sometimes it is reconciliation against another system of record.
The important part is that “pending” should not be a place where users disappear.
A pending state that can become actionable is the difference between a product that feels stuck and one that feels alive.
User-Facing Copy Should Not Become Backend State
A common product risk is when user-facing messaging drifts away from backend reality.
For example, the UI might say “We are reviewing your information” when the backend actually needs the user to retry a step. Or the UI might show “Something went wrong” when the system knows the issue is temporary and recoverable.
This creates unnecessary support volume and user frustration.
A healthier pattern is to derive user-facing copy from stable state categories. The backend preserves the decision and operational context. The product surface translates that into language a person can understand.
The exact copy can be friendly and non-technical. It can be reviewed, localized, and improved over time. But it should still map back to meaningful backend truth.
For example:
- Processing states can say the system is checking information.
- User-action states can explain what the user needs to do.
- Retryable states can offer a clear retry path.
- Manual-review states can set expectations.
- Terminal states can avoid promising a path that does not exist.
Plain language is good, but it should not hide the state machine - it should translate it.
Migrations Are A Test Of State Quality
State quality becomes especially important during migrations.
When teams migrate onboarding flows, identity providers, payment paths, support tooling, or internal review systems, old states and new states often coexist. Some users started in one version of a flow and finished in another. Some internal tools still expect legacy fields. Some support playbooks refer to old labels.
If the state model is vague, migration becomes risky. If the model is explicit, engineering can write compatibility layers, map old states to new states, and retire legacy paths more safely.
Good migrations usually include:
- a state mapping between old and new systems
- a fallback plan for legacy records
- careful handling of in-progress users
- logs for unexpected state shapes
- support visibility during the transition
- a cleanup plan for retired paths
This work is not glamorous, but it protects users from getting stranded between systems.
Why This Matters For Credit Access
For a credit-building product, an explainable state is part of accessibility.
A user who understands their current step is more likely to complete it. A user who knows when they are waiting versus when they need to act is less likely to churn or contact support unnecessarily. A user who sees a clear retry path is less likely to feel rejected by a vague error.
This matters for people who have historically been underserved by traditional credit products. If the product asks them to provide information, connect accounts, verify identity, or complete financial steps, the product should also explain what is happening in return.
Better state design does not guarantee approval. It does something different: it makes the process more legible, recoverable, and respectful.
That is a meaningful engineering contribution.
Takeaways For Engineers
Several principles are reusable across fintech products:
- Treat state as a product contract, not just a database field.
- Separate machine state, user-facing messaging, operational context, and audit history.
- Distinguish retryable failures from terminal outcomes.
- Make retries idempotent.
- Model manual review as a first-class state.
- Define which systems own which transitions.
- Protect important flows from stale writes and invalid transitions.
- Plan for stale state with timeouts, reconciliation, or manual review paths.
- Make support and operations visibility part of the design.
- Use correlation IDs and transition history for debuggability.
- Derive user copy from real backend state categories.
- Plan state mappings carefully during migrations.
Financial products ask users for trust. Explainable state is one way engineers can earn it.
When the state is clear, users know what is happening. Support teams know how to help. Operations teams know what to review. Engineers know how to debug. Compliance teams can understand the path the system took.
That clarity matters most when the product is helping users navigate something stressful or unfamiliar, like onboarding, verification, repayment, or credit building.
In fintech, a state machine is not just backend architecture. It is part of the user experience, the support model, and the trust boundary.
Atlas © Exto Inc. is a financial technology company, not a bank. Banking services provided by Academy Bank, N.A. and Patriot Bank, N.A.
Apply In Minutes
• Just takes two minutes to apply 3
• 0% APR with limits that grow with you
• No credit history needed
By clicking "Get Started" you opt-in to receive account and marketing messages at the entered number and agree to Atlas' terms of service, mobile terms and privacy policy. Message frequency varies. Message and data rates may apply. You can opt-out at any time by replying STOP, or text HELP for support.





