
Fintech Internal Tools Are Risk Systems: How to Build Them Securely


Internal Velocity Needs Guardrails
Fintech internal tools are often described as dashboards, admin panels, or back-office software. That framing misses something important.
An internal tool can help teams investigate payments, resolve disputes, review applications, update account state, inspect sensitive records, and unblock users. That makes it part of the risk system — not just a productivity surface.
Atlas HQ was built with that in mind: an internal operations platform where speed and control are designed together. The goal is to help teams move quickly while preserving least privilege, traceability, review workflows, and clear operational accountability.
Financial operations work often happens in the messy middle. A user may be waiting on a review. A payment may need investigation. A support agent may need to understand why an account is blocked. When teams lack good internal tooling, they compensate with manual work: spreadsheets, one-off scripts, database lookups, chat approvals, tribal knowledge.
That slows the company down, but speed isn't the only concern. Informal operations also make it harder to answer basic questions:
- Who took this action?
- What user or object did it affect?
- Was the actor allowed to do it?
- Was a second approval required?
- What changed?
- Can we find the logs when something goes wrong?
In fintech, those questions aren't optional. They're part of protecting users.
The engineering challenge is avoiding two bad extremes: an internal tool that's fast but too powerful, where broad access creates unnecessary risk — and a control-heavy process so slow that users wait longer for resolution. The better path is controlled velocity.
Treat Every Internal Action As A Product Event
A useful mental model: treat internal actions the same way you treat user-facing product events.
An internal action should have a clear actor, target, reason, permission boundary, request identifier, result, and audit trail. It should be observable. It should fail clearly. It should be testable. It should not depend on someone remembering an informal process.
A simple button in an internal tool is rarely just a button. Behind it, there may be:
- an authenticated internal user
- a permission check
- a request identifier for log correlation
- input validation
- a backend action router
- a business-logic handler
- an audit entry
- an optional approval gate
- a user-facing or ops-facing result
The structure is what lets internal tooling scale safely.
A General Architecture Pattern for Fintech Internal Tools
A simplified internal-tool architecture looks like this:
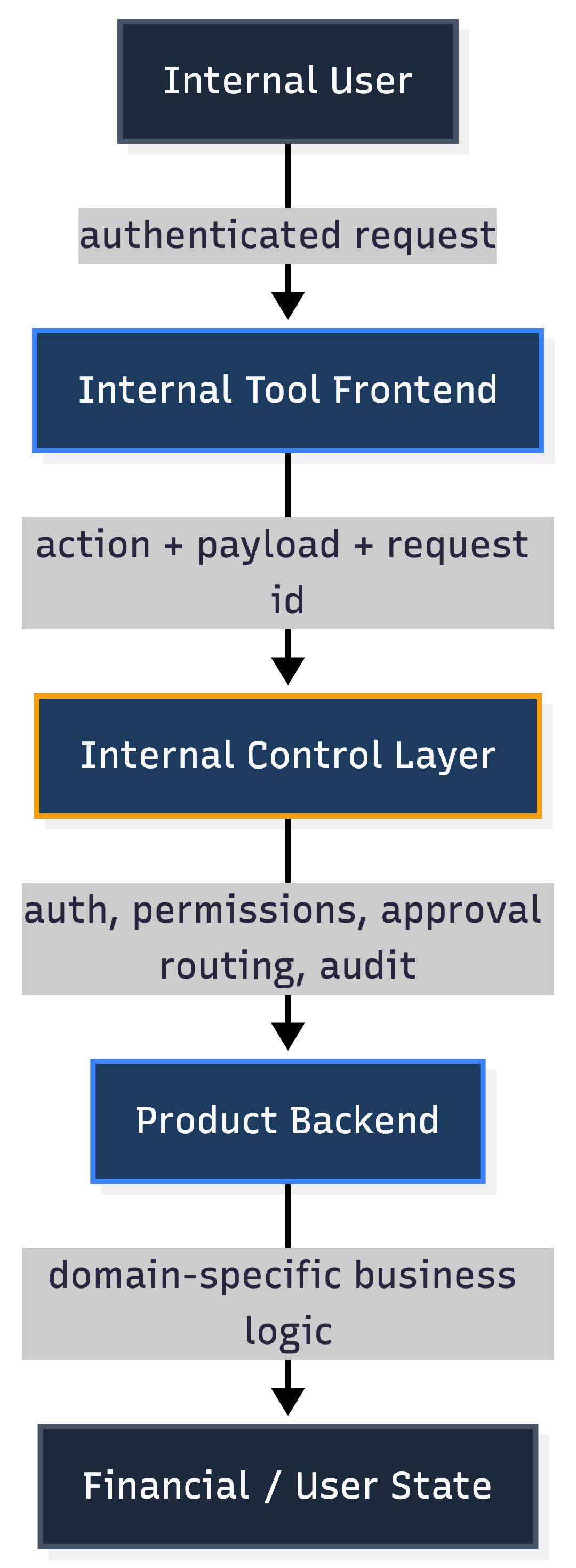
The important part is the internal control layer — the boundary between a convenient UI and sensitive backend capabilities.
That layer should answer several questions before an action reaches product logic:
- Is the actor authenticated?
- Is this action known and governed appropriately?
- Does the actor have permission for this action?
- Does this action require approval?
- Is the payload valid?
- Can the request be traced later?
- How should success or failure be recorded?
Without this boundary, internal tools accumulate implicit trust. With it, they can be safer and faster at the same time.
To make the pattern concrete: consider reversing a financial operation that has already posted. An operator triggers the action from the internal tool. The frontend sends the action, payload, and authenticated context through the internal control layer. The layer verifies the actor, checks permissions, attaches a request identifier, and evaluates whether the action needs approval. If it does, the system captures the request and routes it to an authorized reviewer. A different reviewer approves or denies it. If approved, the system executes through the controlled backend path, records the result, and ties everything back to the approval request and request ID. Every step is observable, permissioned, and recoverable.
From Role-Based Access To Action-Level Control
Traditional role-based access control is a good start. Admins, support agents, risk reviewers, and operations leads shouldn't all have the same access.
But fintech operations often need finer control than broad roles provide. Two actions may live on the same page but carry very different risk. Viewing a record, adding a note, re-running a check, approving an exception, and changing financial state shouldn't necessarily share the same permission.
Action-level permissions solve this. Instead of asking only "what page can this person open?", the system can ask "what exact operation is this person allowed to perform?"
A useful implementation pattern: maintain action mappings as a shared source of truth for restricted operations. Adding a sensitive capability means adding an action mapping and assigning the appropriate roles — not wiring trust into the UI. Retiring or changing a capability means updating the control layer, not hunting through every button and page.
Permissions and approvals can also be modeled as separate but connected controls. An action mapping decides who may start an action. Approval configuration decides which sensitive actions require review before execution. Activity logging records what happened. The result is better security and clearer ownership.
Approval Gates For High-Risk Operations
Some actions shouldn't run immediately, even when the requester has permission to start them.
For those cases, an approval workflow creates a second layer of control. The requester submits the action, the system captures the relevant context, and an authorized reviewer approves or rejects it.
The design details matter:
- The requested action should be captured clearly.
- The approver should see enough context to make a decision.
- The approval decision should be recorded.
- The final execution path should be tied back to the approval request.
- The system should avoid ambiguous states like "maybe approved" or "ran outside the approval record."
Two controls deserve special emphasis.
Segregation of duties: The person who requests a sensitive action should not be the person who approves it. No self-approval is one of the most effective controls in financial operations.
Controlled execution: At execution time, the system should avoid blindly replaying stale approvals. A strong approval flow ties execution to the stored approval request, uses controlled status transitions, and records a fresh execution request ID. Domain-specific validation still belongs in the backend action itself.
Approvals are both a control mechanism and a feedback loop. If many requests are approved, the policy may be too strict. If many are rejected, the initiating workflow may need better guidance. If reviewers frequently need more context, the internal tool may need to surface better state.
Migration Is A Product Problem
Replacing legacy internal tooling is not only an engineering migration — it's a workflow migration.
Operators build habits around tools. They remember where buttons are, which fields matter, which labels mean "safe," and which screens help them resolve a user issue. A new tool that is technically better but operationally unfamiliar can slow teams down considerably.
Parity matters during migration. The new platform needs to preserve the behaviors users rely on while improving the underlying control model. That means matching important labels and statuses, preserving familiar search paths, keeping high-frequency actions easy to find, and making failures clearer than before.
The goal is to move safely from a familiar system to a more governed one — not to copy every legacy detail forever.
Engineering Velocity And Developer Autonomy
A strong internal platform makes safe behavior the default path for engineers.
Without a shared platform, every new internal workflow has to reinvent authentication, permission checks, approval routing, audit logging, request tracing, and error handling. That creates inconsistency and slows teams down, because every feature becomes both a product problem and a controls problem.
The better pattern is to move the repeated control logic into the platform layer. When engineers add a new internal capability, the platform should already provide the common pieces: authenticated agent identity, permission resolution, request IDs, activity logging, approval routing for elevated-risk actions, and consistent error responses. Feature teams can then focus on the domain workflow itself.
Internal-tool velocity comes from standardizing risk controls, not bypassing them.
Make Money-Moving Actions Idempotent
In a financial system, doing something twice can be as harmful as not doing it at all.
Operators double-click. Networks retry. A request times out on the client but succeeds on the server. If an internal action moves money, adjusts a balance, or changes account state, it has to be safe to reason about when retried.
The standard engineering concept is idempotency: repeating the same logical operation shouldn't accidentally create multiple outcomes. Request IDs help make this possible — they give engineers and operators a stable handle for tracing what happened. But request IDs alone don't guarantee exactly-once behavior. The domain backend or workflow state still has to enforce duplicate protection.
This is easy to defer and expensive to retrofit. For internal tools that touch money or account state, retry behavior belongs in the first version, alongside permission checks and audit logging.
Audit Trails Must Be Useful
An audit trail is only useful if it helps someone understand what happened after the fact.
For financial operations, that means more than logging that a button was clicked. A useful audit record captures the actor, action, target, sanitized parameters, request identifier, result, and relevant error or approval metadata. For higher-risk changes, capturing prior state or before/after context makes review stronger.
The most important principle is consistency: audit data should be written as part of the action path, not reconstructed later from scattered logs and screenshots.
Good audit design helps multiple teams:
- Support can understand what happened without asking an engineer to search raw logs.
- Operations can review patterns and exceptions.
- Compliance can inspect decision paths with better context.
- Engineering can debug failures using request IDs and structured metadata.
Log the right things, in a form that can be searched, reviewed, and trusted.
Monitoring Before Enforcement
One useful migration strategy: introduce controls in monitoring mode before blocking execution.
In monitoring mode, the system records which actions would have required approval or which usage patterns may exceed a policy — without immediately interrupting operators. This helps teams understand real workflows before enforcing a new rule. It's especially useful during migrations from legacy tools, where existing workflows may contain edge cases that aren't written down anywhere.
Once the team understands the impact, the same control can move from observation to enforcement. This reduces rollout risk and builds trust with operators, because new controls arrive with evidence rather than guesswork.
Request IDs Make Operations Debuggable
When something goes wrong in a distributed system, "the button failed" is not enough information.
Internal tools need request identifiers that travel across the frontend, internal control layer, product backend, and logs. A request ID lets an engineer or operator connect the user-facing result to backend execution — on success, to confirm what happened; on failure, to diagnose whether the problem was validation, permission, approval routing, backend logic, a downstream dependency, or a timeout.
For internal users, a request ID is also a support tool. Instead of asking an engineer to search loosely by time or user, an operator can provide a precise correlation handle. That's the difference between a black box and an accountable system.
Internal Tools Protect External Users
Most users will never see Atlas HQ. But they are affected by its quality.
When internal tools are reliable, users get faster help. When permissions are narrow, users are better protected. When actions are audited, unexpected changes can be investigated. When approval gates exist for sensitive operations, users benefit from more careful review.
This is why internal tools should be treated as user-impacting systems. The interface is internal, but the consequences are external. For fintech engineers, that's the central point: internal operations platforms aren't secondary software. They are part of the product's safety infrastructure.
Lessons For Engineers
A few principles worth carrying to other systems:
- Model internal actions explicitly, with a clear actor, target, permission boundary, and audit trail.
- Prefer action-level permissions over page-level trust.
- Separate permission checks from approval workflows — they solve different problems.
- Use approval gates for elevated-risk operations, and enforce no self-approval.
- Make money-moving actions idempotent at the domain layer, not just at the request layer.
- Add request IDs that follow the action across every system boundary.
- Build audit trails into the first version — retrofitting them is expensive and incomplete.
- Consider monitoring mode before enforcement, especially during legacy migrations.
Apply In Minutes
• Just takes two minutes to apply 3
• 0% APR with limits that grow with you
• No credit history needed
By clicking "Get Started" you opt-in to receive account and marketing messages at the entered number and agree to Atlas' terms of service, mobile terms and privacy policy. Message frequency varies. Message and data rates may apply. You can opt-out at any time by replying STOP, or text HELP for support.

.jpg)



